df = pd.read_csv('possum.csv', usecols=['skull_w', 'head_l'])
df.head()| head_l | skull_w | |
|---|---|---|
| 0 | 94.1 | 60.4 |
| 1 | 92.5 | 57.6 |
| 2 | 94.0 | 60.0 |
| 3 | 93.2 | 57.1 |
| 4 | 91.5 | 56.3 |
I remember first time learning regression and remember the bullet points of assumptions. I believe people still learn that way, knowing that multicollinearity is an issue. But, what exactly is the issue? If you are following my posts on the basketball analytics newsletter, adjusted plus-minus (APM) models are actually up against same issue.
Anyway, let’s get into it with an example. Btw, I’m going to using a Bayesian regression on this one since I feel like it makes the example more intuitive. However, feel free to give it a go with the frequentist way, which you’ll end up noticing similar things.
df = pd.read_csv('possum.csv', usecols=['skull_w', 'head_l'])
df.head()| head_l | skull_w | |
|---|---|---|
| 0 | 94.1 | 60.4 |
| 1 | 92.5 | 57.6 |
| 2 | 94.0 | 60.0 |
| 3 | 93.2 | 57.1 |
| 4 | 91.5 | 56.3 |
You probably remember the possum data from other posts. Let’s predict head_l from skull_w. But I’ll do something extreme, I’ll add exact copy of skull_w and put both the original and the copy into the model.
But before, here’s what it looks like with a simple linear regression (the frequentist way).
model = smf.ols('head_l ~ skull_w', data=df)
res = model.fit()
res.summary().tables[1]| coef | std err | t | P>|t| | [0.025 | 0.975] | |
| Intercept | 46.1954 | 4.554 | 10.145 | 0.000 | 37.163 | 55.227 |
| skull_w | 0.8158 | 0.080 | 10.207 | 0.000 | 0.657 | 0.974 |
Around 0.816 — keep that in mind.
az.plot_posterior(trace, var_names=['skull_w', 'skull_w_copy', 'beta_sum'], hdi_prob=.89)array([<Axes: title={'center': 'skull_w'}>,
<Axes: title={'center': 'skull_w_copy'}>,
<Axes: title={'center': 'beta_sum'}>], dtype=object)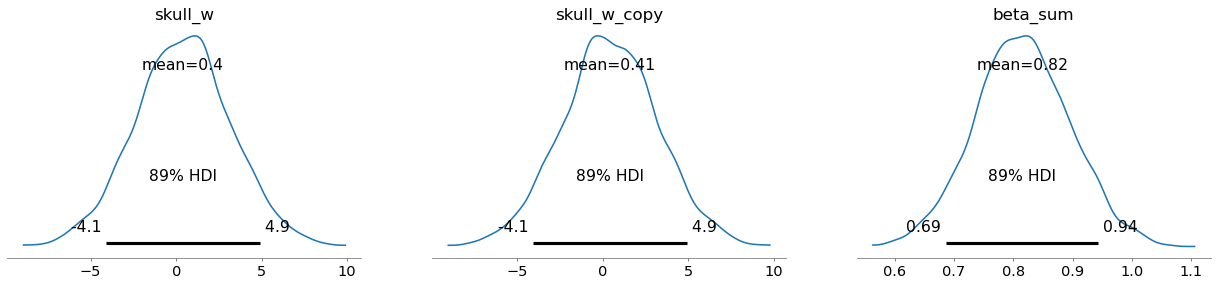
skull_w_dist = trace.posterior['skull_w'][0]
skull_w_copy_dist = trace.posterior['skull_w_copy'][0]
plt.figure(figsize=(7, 5))
plt.scatter(skull_w_dist, skull_w_copy_dist, s=15, alpha=.43)
for i in range(10):
print((float(skull_w_dist[i]), float(skull_w_copy_dist[i])))(3.9048626538535167, -3.1255189869958886)
(-2.9323664950018005, 3.808560558848153)
(-0.253518722705609, 1.12998380832265)
(-1.7757320956912432, 2.644872542399044)
(-1.1693805471416598, 2.0054535527772908)
(-5.312591811956688, 6.1362012177510135)
(-3.6857422924962964, 4.417532979288446)
(0.46372693930833064, 0.20153951513903898)
(-1.3630216489906541, 2.000311282396281)
(1.2653379661450885, -0.2655350255316545)Okay, the things that get attention on the first row of plots:
beta_sum: It’s centered around 0.82 with not so wide range. It’s because only the sum is identifiable.Unidentifiability means that the model does not make it possible to estimate the value of the parameter. Multicollinearity falls into this bucket of problems.
The second plot is showing actually what’s going on. After knowing the value of one, what’s the value of the other? Well, both variables carry the same information. Hence, as you know one the other doesn’t help much — ridge of equally plausible joint values.
\(\displaystyle y = \beta_{0} + \beta_{1}X_1 + \beta_{2}X_2\)
Those variables are the same in our example, so let’s denote both as X.
\(\displaystyle y = \beta_{0} + \beta_{1}X + \beta_{2}X\)
Which leads to:
\(\displaystyle y = \beta_{0} + (\beta_{1}+\beta_{2})X\)
Hence, they are not separable. The effect on y is their sum.
Alright, so, is the model wrong?
Nope. You just can’t separate the effect of either variable, so you can’t make up your mind about which one is more important. Predictions will be just fine, if that’s what you care about.
fig, ax = plt.subplots(1, 1, figsize=(7, 5))
az.plot_ppc(
trace,
group='posterior',
kind='kde',
num_pp_samples=200,
ax=ax
)
plt.title('With both included')Text(0.5, 1.0, 'With both included')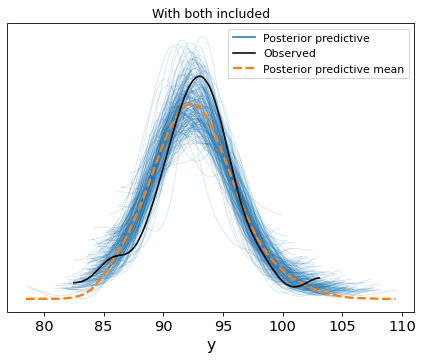
fig, ax = plt.subplots(1, 1, figsize=(7, 5))
az.plot_ppc(
trace,
group='posterior',
kind='kde',
num_pp_samples=200,
ax=ax
)
plt.title('With only one included')Text(0.5, 1.0, 'With only one included')
I hope this post helps with internalizing what the issue is with multicollinearity, and sheds light into identifiability. I’ll keep up with stats posts in the future. Until next time, take care.